In spring 2024, I completed Vivaldi’s developer build assistance transition from Goma to the newer Reclient system. Goma and Reclient are remote build assistance that can perform compilation of files that you need to build, but do so on remote computers (workers), managed by […]
Category: Technology
Broken Windows Updates
Every month Microsoft releases security updates on the second Tuesday of the month in order to remove security problems in the installations of the Windows Operating System. January 9th was no exception, but this time there was a problem. One of the updates (KB5034441) […]
The trouble with Chromium translations

Most applications that are intended for a broad international audience have their UI translated to various languages, the number of which can vary widely, depending on the resources of the vendor, especially their ability to recruit translators. Vivaldi is currently being translated to 91 […]
Microsoft, you broke Visual Studio!
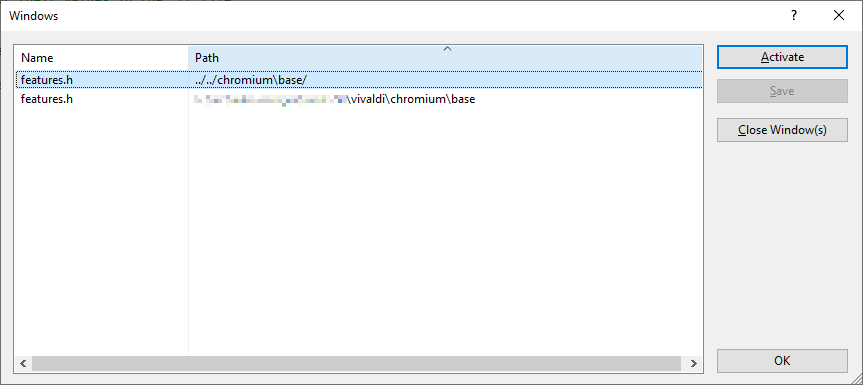
One of the most important tools when developing software is a good development environment, called an IDE (Integrated Development Environment), with at least an editor, build functionality, debugger, and being able to go directly from a compile error listed in the compiler output to […]
Soooo … you say you want to maintain a Chromium fork?
Photo by Ari Greve (Note: this article assumes you have some familiarity with Git terminology, building Chromium, and related topics) Building your own Chromium-based browser is a lot of work, unless you want to just ship the basic Chromium version without any changes. If […]
Microsoft! You broke my backup system!
Backing up the data on your computer is one of the most frequently given advice to computer owners, and there are a number of ways to accomplish it. The oldest way is to copy the data to an external media. Originally this was tapes, […]
Ars Technica’s privacy-invading Privacy Policy update
Ars Technica is one of the major technology news sites I follow, as it carries a lot of interesting stories about computer, general technology, and science news. Last week, however, reading the site became much more difficult. In relation to the California Privacy law […]
Sophos: An update
Two weeks ago I posted an article about the occasional problems of getting false positives in security software fixed, and specifically about our recent problems when trying to solve a problem related to a Sophos security product. A user had reported being prevented from […]
The problem with unsophosticated customer support
False positives causing a legitimate application to be blocked is a common problem with security software, and if not handled properly and quickly, it is one that could hurt, or even destroy a security product’s credibility, or in the worst case, the credibility of […]
Where did all the nice things go? SmartGit project dropdown
For modern software developers, there are a number of must-have tools: An editor, a compiler (called a web browser by HTML/JS devs), and a debugger. Further, if you are developing a non-trivial project, especially as part of a team, you will need a version […]