Every month Microsoft releases security updates on the second Tuesday of the month in order to remove security problems in the installations of the Windows Operating System.
January 9th was no exception, but this time there was a problem. One of the updates (KB5034441) failed with the error number 0x80070643, and kept failing on several machines. I paused updates and when updates resumed a week later the patch was gone.
Fast forward to last week, February 13th, and the problematic update is back, and still failing.
According to the MS support article this patch is for something in the Windows Recovery system, related to a problem with the BitLocker file system encryption, and it updates a special partition on the disk (on the systems I have checked it is 500 MB) and the patch claims it needs 250 MB free (there is no information about how much is available in the Windows Computer Management disk info).
Following the failures on many systems, Microsoft posted another article with instruction of how to manually resize the partition so that the patch would apply.
I have several problems with those instructions:
The instruction are very advanced, requiring the user to resize an existing disk partition with data to free up space. This is an operation I only undertake when installing a system, before I actually store data on the system. The worst that can happen is that the data in the partition are lost.
Further, once the partition has been reduced, the user have to run a highly specialized command as administrator in the terminal window to resize/recreate the recovery partition.
Neither of these are actions are something I (a fairly advanced user) would like to undertake on my own production systems, much less in combination, and I suspect that a normal user would refuse to even consider it.
Actually, I further suspect that most normal users wouldn’t even be aware that the update was failing. There is no indication or notification in Windows that a patch failed to apply, and a normal user will just find their PC rebooted the morning after it applied patches, and conclude that the PC is fully up to date and secure. I only know the patch is failing because the last two months I wanted to control when and how my PC rebooted to apply the patches so that it didn’t disrupt what I was working on.
What this means that, assuming this is a patch for a severe issue (and as it have something to do with bypassing the BitLocker disk encryption, it is severe), most users for which this patch is failing are probably blissfully unaware that they have an unpatched security problem on their machine.
Where is the Press?
What I have noticed about this issue is that AFAICT few of the online news services I monitor seems to have reported on the problem. I have noticed at least one Twitter thread, some MS forums threads, but no news media articles.
The Register (which bills itself as “Biting the hand that feeds IT”), did post an article in January, but have not yet followed up after the February repeat. Others, like ArsTechnica and The Verge seems to not have noticed.
What needs to be done?
What Microsoft needs to do about this patch is that it must fixed so that it is able to safely complete its operation without disturbing the user, or requiring the user to manually change their system.
I also think that the patch should be made to complete successfully without changing partition sizes. To paraphrase what Bill Gates reputedly said: “500 MB should be enough for any recovery partition.”
Most applications that are intended for a broad international audience have their UI translated to various languages, the number of which can vary widely, depending on the resources of the vendor, especially their ability to recruit translators.
Vivaldi is currently being translated to 91 languages, a few more than Chrome.
Under the hood Vivaldi’s UI string (“string”: The term used in computer programming for a section of text) translation system actually consists of two independent systems, the Chromium one, and the system used by Vivaldi’s native UI.
This article will only cover the Chromium system and the challenges of using it.
The Chromium string/text translation and resource system consist of two kinds of files:
The GRD files, which can declare the US English version of the strings, and the location of various file resources like icons and documents (HTML, JS, CSS) used by the Chromium UI, and
The XTB files, one for each language, contain the various translations of the original strings in the associated GRD file.
When building the product (Vivaldi, in our case) these files are processed by various scripts in the build system and converted into files that can be handled by the Chromium code handling strings and the resources.
One of the challenges for a product like Vivaldi is that the strings and resources defined by the Chromium project are very specific to Chromium and Google Chrome, such as logos and the company and product names used in the string.
Of course, we in Vivaldi want to use the Vivaldi logo, and to use “Vivaldi” and name of the product and company. Duh!
That means that we have to change the resource definitions and the strings (and translations) to use Vivaldi’s preferred resources and names.
However, if you’ve read my article about maintaining a Chromium fork, you will have noticed that I said that you should never modify the Chromium translation files. Yet, I just said above that to use our preferred resources and strings we have to change the files. Why should we not change the files, and how do we work around the problem to still be able to use our chosen resources?
The reason why we should not change the files comes down to two reasons:
First, the Chromium resource files are frequently updated by the Chromium team. New resources and new strings are added, and old ones are changed to improve their meaning, and occasionally some are removed. All of these changes mean that when upgrading the Chromium source code, there is a significant risk that these changes will occur to the specific lines of the file we modified, or close to them. That means that we would have to resolve the conflicts between the new text and our changes, which will significantly increase the time needed to complete the update.
Second, for the strings we would have to not just modify the GRD file entry, we would have to modify the corresponding entry in each of the 80+ translation XTB files associated with each file, and to top it off, each of those entries has a numeric identifier calculated from the original string in the GRD file, so if you change the original string, you have to recalculate the value and update each XTB file for that entry. Ouch! Lots of work. Additionally, each of those updated entries in each file is another possible update merge conflict that has to be resolved manually. Double ouch!
So, how do we resolve this problem? How do we update the resources, strings, and translations without modifying the Chromium resource files? The answer is that we do change them, but we don’t change them.
What we have done in Vivaldi is to create our own resource GRD and XTB files for each set of Chromium resource files that we want to update, and add our file resources, strings, and translations in these files. The translation files are usually used to add the translations for the extra languages we support, but in some cases we do an extensive rewrite of the original string, which require more translations to be added in our version.
Then, while building the application we have updated the project and the scripts it used to automatically insert our updated changes into the data, before they are used to generate the binary files used by the application.
The result is that we don’t have to update the original files, but we can update the resources, strings, and translations.
This process is also used to automatically replace mentions of Chromium and Google Chrome company and product names with Vivaldi’s name, both in the original US English strings and the translations. This process does have its challenges, especially since “Google” is frequently used in combination with other words to name products we don’t support, like “Google Pay”, so we have to exclude such replacements.
Occasionally, there are strings that mention the Google, Chrome, or Chromium names when replacing them with Vivaldi is not desirable (and an example just showed up in the forums https://forum.vivaldi.net/topic/77930/wtf-what-the-floc-google-s-still-at-it/2?\_=1661690451983\, where information about a system Google is working on said Vivaldi instead, that has now been “fixed”), and in these cases, we exclude that particular string from being replaced.
Another recent example was the string “Chrome is made possible by the Chromium open-source project”, which was auto replaced into “Vivaldi is made possible by the Vivaldi open-source project”, not “Vivaldi is made possible by the Chromium open-source project”. Oooops! That was fixed by adding a full override of the text with correct wording.
Could we avoid using this kind of system? Well, it is not the only way to implement such a system.
One could add an independent set of resource files (and we have those for our own), and add our replacements in those files using different identifiers for them and replace the originals everywhere they are used. However, we would still have the problem with later updates, both of the strings and their meaning, and starting to use them elsewhere (which would have to be discovered and updated). Then there is the issue of more potential merge conflicts during updates.
Quite simply, using different identifiers would not work very well, since their use would have to be maintained continuously. Just replacing the original entries will generally work better.
And that ignores the use of product names in many strings. There are a lot of those names used around the code, and copying and modifying them into a different set of files would be a major undertaking, and would still have to be updated with new strings every Chromium upgrade.
The best way to avoid the search and replace of product names (and thus avoid the funny cases) would be for the Chromium team to stop using “Google”, “Google Chrome”, “Chromium” etc. hardcoded into the strings, but instead using variables that can insert the downstream project’s own preferred name in those strings. This kind of project would be a major undertaking by the Chromium team, and I sort of doubt they would be willing to take it on.
What do the other Chromium-based browser teams do? I have absolutely no idea. Maybe they use a similar system, or they have found their own way to manage the issue.
One of the most important tools when developing software is a good development environment, called an IDE (Integrated Development Environment), with at least an editor, build functionality, debugger, and being able to go directly from a compile error listed in the compiler output to the broken part of the code.
On Windows, my primary tool for this is Visual Studio, although I also use Eclipse for some projects, mostly involving scripting.
For the past few years, I’ve been using Visual Studio 2019, the then current version, but a few months ago I started using the newer 2022 version. Unfortunately, I quickly discovered that I can’t really use it for my major work task: Getting Vivaldi to build again after a Chromium upgrade, because important functionality broke in that version. The result is that I am back to using VS 2019 for that task.
When I am recompiling Vivaldi after a major Chromium upgrade (a process that can take several days), there will be a lot of compile errors (mostly due to changes made by the Chromium team no longer with our own code) that will need to be fixed, and it is very useful to be able to just click on the compile error and get to the exact line in the code where the problem was encountered.
Both VS 2019 and VS 2022 have this functionality, but in VS 2022 it is partially broken, to the extent that it is unusable for a major operation like getting an updated source base to work again, with 100+ files failing to build properly.
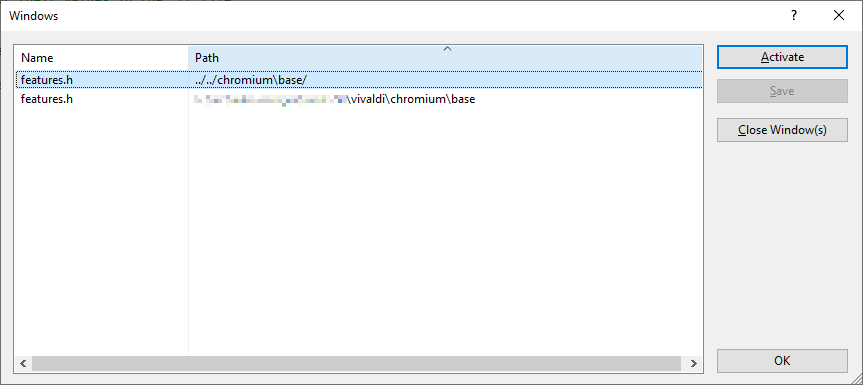
The problem is that, while VS 2022 opens the correct file, it doesn’t open it in the “right” way.
The compile error output writes the filename location as relative to the build directory (in my case out/Release), e.g. ../../chromium/chrome/foo.cc, and VS 2022 opens it with that path, relative to the build directory, not using the absolute path drive:/src/project/chromium/chrome/foo.cc which it uses for files opened any other way, as you can see from the screenshot at the top.
It may be that Visual Studio’s own compiler always prints the absolute path in the compile errors, which might explain how this issue was not discovered in testing, but Chromium-based projects no longer use that compiler to build Chromium, they use the LLVMClang compiler, which outputs relative paths to the file with the error.
The result is several problems, first of all, there can be two tabs open for the same file, and this means that you won’t have access to the edit history of the other file, and having multiple tabs supposedly viewing the same file is a problem if the tabs are out of sync with each other.
Second, these extra tabs are not integrated into Visual Studio’s “Intellisense” system, which parses the code, indicating errors, and can be used to find definitions of functions and classes. Although … Intelllisense no longer works even close to as well as it did 20ish years ago, in Visual Studio 6, in fact using Find in File works usually better.
As mentioned, opening the code in a tab works well in VS 2019, so something got broken along the way between VS 2019 and VS 2022. Probably there is only a call to a function or two to create an absolute path of the file path that is missing.
I reported this issue in June to MS via two of their Twitter accounts as reporting bugs via Visual Studio requires that you log into the system, which requires an account, and I don’t create new accounts at the drop of a bug (or shoe), I generally only do so when I am going to actively use the account for several years. In any case, reporting a bug should not require an account on the system.
As far as I can tell from searching the Known Issues list (using its bad search engine, they might want to talk to some search engine developers) for Visual Studio, my report had not been added a few weeks ago.
However, this is not the only problem with VS 2022.
Among the reasons for moving to VS 2022 was that it is now built as a 64-bit executable, not a 32-bit like before, which should make it better able to manage gigantic projects like the ones based on Chromium. The full Chromium project (even Vivaldi’s relatively lightweight one which does not include all support sub-projects) consumed so much memory when loaded in the old 32-bit VS 2019 that it tended to hit the 3 GB RAM roof and crash, especially in the middle of debugging an issue. A 64-bit executable should be able to handle much larger projects as long as the machine have enough memory installed (and mine have 128 GB RAM).
Unfortunately, VS 2022 does not seem to be very stable at present and has even crashed while being idle in the background (that is, it crashed even if you were not looking at it the wrong way), although I am not sure if that is still the case after the most update, although it still crashes at times.
In other words, at present Visual Studio 2022 is a major disappointment.
Back in (pre-covid) 2019 I posted an article asking where the nice things disappeared to, including where the shoe brand I have been using for ~20 years walked off to. It was 8 (now 10) years since I had last been able to buy any Rockport XCS shoes (which is the only ones I have found that give my feet proper support under the arches), and the ones I had was starting to wear out, despite repeated repairs.
After the article, Rockport did provide some information about where I might be able to buy Rockport shoes, in Oslo, London, and in the US, but not necessarily where to get the specific XCS sub-brand I am using.
When checking the Oslo stores they named, they had none of the shoes I was looking for, and almost no Rockport shoes at all, and there were stores selling Rockport that were not mentioned by Rockport. I never got around to checking the London stores, as by the time I had planned to go the world had locked down, and thrown away the key.
When I later talked to one of the stores I knew about that had previously sold Rockport, they told me that they wanted to sell Rockport shoes, but weren’t able to get hold of any from their distributors.
All of this suggests several problems regarding Rockport’s way of doing business.
Not only have they entered bankruptcy twice in the past 4-5 years, but they are not doing a good job getting the shoes out to interested stores and customers. And even the stores that are able to get shoes are apparently not able to get many.
Recently, I was at Vivaldi’s annual gathering outside Boston (incidentally, just a few kilometers from where Rockport got started, in the town of Rockport, MA) and used the opportunity to look for suitable new shoes.
Rockport did tell me that a couple of major chains, Macy’s, Nordstrom, DSW, were selling them. Macy’s was the only one that had a couple of the XCS sub-brand, but none were the right size (as they did not sell the wide size variation I need). I did locate another store that had some, but they only had two pairs, of the wrong size.
I had to resort to what I absolutely did not want to do: Buy shoes online. The reason I don’t want to do that, is that I want to see and fit the shoe before I buy it. Just call me old-fashioned.
While I did have to return one pair of shoes to Amazon because they were the wrong size (not wide enough, which would have caused blisters), I eventually did manage to get a new pair of sandals, a new pair of winter shoes, and new summer shoes (three pairs, since I decided to make sure I would have some for a while, just in case it got difficult to find suitable shoes again). The only reason I was able to manage with just one return was that I was very careful about what I ordered (and only ordered the extra pairs after testing a pair).
I think the way Rockport has been doing business is making a lot of trouble and causing lost sales for them.
First, they are no longer providing customers with an online list of stores that sell their shoes. 10 years ago they did have one, and it was searchable based on which city you were in. With proper integration with a modern sales system such a list should be able to not just tell the customer which stores sell Rockport, but which specific shoes they have in stock.
Second, they closed all the dedicated Rockport stores which were found in various major cities in the US and perhaps elsewhere in the world. These stores were where I bought most of my shoes, because they had the widest selection.
Third, the website/online store where they market their shoes has trouble listing just the XCS shoes (or the other technologies they offer), and the search shows up irrelevant shoes. It was frequently necessary to look carefully on the photos to discover if they were the right kind. They really need to improve the website search capability.
Amazon isn’t much better in the search area, their results also include irrelevant results when searching for “Rockport XCS”, and if you add “men’s shoes” (which is one of their search suggestions) you get a lot of other brands included in the results.
Fourth, they are apparently making it really hard for small Brick-and-Mortar retailers, at least in Europe, to obtain shoes they can sell to their customers. And that might actually cause them further sales losses. A few weeks ago one of Norway’s major newspapers published a story (in Norwegian) about how online shopping, especially clothes and shoes, was declining, and shopping in normal stores was growing.
The result is that Rockport doesn’t tell and doesn’t show potential customers about what they offer, doesn’t tell them where they can buy, and doesn’t tell stores where they can get wares. The “only” place you can reliably get them is Amazon (and the Rockport online store, but I don’t create new accounts at the drop of a shoe), and shoes are one of the wares that are better sold in Brick-and-Mortar stores.
The result of don’t tell, don’t show, is that you don’t sell. And neither do the stores that want to sell your wares, so they go on to sell your competitor’s shoes instead.
(Note: this article assumes you have some familiarity with Git terminology, building Chromium, and related topics)
Building your own Chromium-based browser is a lot of work, unless you want to just ship the basic Chromium version without any changes.
If you are going to work on and release a Chromium-derived browser, on the technical side you will need a few things when you start with the serious work:
A Git source code repository for your changes
One or more developer machines, configured for each OS you want to release on
Test machines and devices to test your builds
Build machines for each platform. These should be connected to a system that will automatically build new test builds for each source update, and your work branches, as well as build production (official) builds. These should be much more powerful than your developer machines. Official builds will take several hours even on a powerful machine, and requires a lot of memory and disk space. There are various cloud solutions available, but you should weigh time and (especially) cost carefully. Frankly, having your own on-premises build server rack may cost “a bit” up front, but it lets you have better control of the system.
A web site where you can post your Official builds so that your users can download and install them
Now you are good to go, and you can start developing and releasing your browser.
Then … the Chromium team releases a new major version (which they do every 4 or 8 weeks, depending on the track) with lots of security fixes. Now your browser is buggy and unsecure. How do you get your fixes to the new version?
This process can get very involved and messy, especially if you have a lot of patches on the Chromium code. These will frequently introduce merge conflicts when updating the source code to a newer Chromium version because the upstream project have updated the code you patched, or just nearby, but there are a few things you can do about that to reduce the problems.
There are at least two major ways to maintain updates for a code base: A git branch, and diff patches to be applied on a clean checkout. Both have benefits and challenges, but both will have to be updated regularly to match the upstream code. The process described below is for a git branch.
The major rule is to put all (or as much as practical) of your additional independent code that is whole classes and functions (even extra functions in Chromium classes) in a separate repository module that have the Chromium code as a submodule. Vivaldi uses special extensions to the GN project language to update the relevant targets with the new files and dependencies.
Other rules for patches are:
Put all added include/imports *after* the upstream includes/import declaration.
Similarly, group all new functions and members in classes at the end of the section. Do the same for other declarations.
Any functions you have to add in a source file should always be put at the end of the file, or at the end of an internal namespace.
Generally, try to put an empty line above and below your patch.
Identify all of your patches’ start and end.
Don’t change indentation of unmodified original code lines, unless you have to (e.g. in Python files).
Repetitive patching of the same lines should be fixuped or squashed. Such repetitions have the potential to trigger multiple merge conflicts during the update, which could easily cause errors and bugs to be introduced.
NEVER (repeat: NEVER!!!) modify the Chromium string and translation files (GRD and XTB). You will be in for a world of hurt when strings change (and some tools can mess up these files under certain conditions). If you need to override strings add the overrides via scripts, e.g. in the grit system merging your own changes with with the upstream ones (Vivaldi is using such a modified system; if there is enough interest from embedders we may upstream it; you can find the scripts in the Vivaldi source bundle if you want to investigate).
Vivaldi uses (mostly) Git submodules to manage submodules, rather than the DEPS file system used by Chromium (some parts of Vivaldi’s upstream source code and tools are downloaded using this system, though). Our process for updating Chromium will work whichever system is used, with some modifications.
The first step of the process is identifying which upstream commit (U) you are going to move the code to, and what is the first (F) and last (L, which you create a work branch W for) commit you are going to move on top of that commit. If you have updated submodules you do this for those as well.
(There are different ways to organize the work branch. We use a branch that is rebased for each update. A different way is to merge the upstream updates into the branch you are using, however this quickly gets even messier than rebasing branches, especially when doing major updates, and after two years of that we started rebasing branches instead.)
The second step is to check out the upstream U commit, including submodules. If you are using Git submodules you configure these at this stage. This commit should be handled as a separate commit, and not included in the F to L commits.
Then you update the submodules with any patches, and update the commit references.
The resulting Chromium checkout can be called W_0
Now we can start moving patches on top of W_0. The git command for this is deceptively simple:
git rebase --onto W_0 F~1 W
This applies each commit F through to L (inclusive) in sequence onto the W_0 commit and names the resulting branch W.
A number of these commits (about 10% of patched files in Vivaldi’s source base) will encounter merge conflicts when they are applied, and the process will pause while you repair the conflicts.
It is important to carefully consider the conflicts and whether they may cause functionality to break, and register such possibilities in your bug tracking system.
Once the rebase has completed (a process that can take several workdays) it is time for the next step: Get the code to build again.
This is done the same way as you normally build your browser, fixing compile errors as they are encountered, and yet again registering any that could potentially break the product. This is also a step that can take several work days. A frequent source of build problems are API changes and retired/renamed header files.
Once you have it built and running on your machine, it is time to (finally) commit all your changes and update the work branch in the top module and push everything into your repository. My suggestion is that patches in Chromium are mostly committed as “fixups” of the original patch; this will reduce the merge conflict potential, and keeps your patch in one piece.
Then you should try compiling it on your other delivery platforms, and fix any compile errors there.
Once you have it built and preferably have it running of the other platforms, you can have your autobuilders build the product for each platform, and start more detailed testing, fixing the outstanding issues and regressions that might have been introduced by the update. Depending on your project’s complexity, this can take several weeks to complete.
This entire sequence can be partially automated; you still have to manually fix merge conflicts and compile errors, as well as testing and fixing the resulting executable.
At the time of writing, Vivaldi has just integrated Chromium 104 into our code base, a process that took just over two weeks (the process may take longer at times). Vivaldi is only using the 8-week-cycle Extended Stable releases of Chromium due to the time needed to update the code base and stabilize the product afterwards. In our opinion, if you have a significant number of patches, the only way you can follow the 4 week cycle is to have at least two full teams for upgrades and development, and very likely the upgrade process will have to update weekly to the most recent dev or canary release.
Once you get your browser into production every couple of weeks you are going to encounter a slightly different problem: keeping the browser up to date with the (security) patches applied to the upstream version you are basing your fork on. This means, again, that you have to update the code base, but these changes are usually not as major as they are for a major version upgrade. A slightly modified, less complicated variant of the above process can be used to perform such minor version updates, and in our case this smaller process usually takes just a few hours.
Backing up the data on your computer is one of the most frequently given advice to computer owners, and there are a number of ways to accomplish it.
The oldest way is to copy the data to an external media. Originally this was tapes, today it will frequently be one or more external harddrive or SSD. Swapping between at least two complete backups is recommended, with the inactive drives stored off-site to avoid destruction or loss in case of fire, theft, or other disasters (and if your area is prone to major disasters, it might be an idea to occasionally store a backup copy in a safe location hundreds of kilometers away; storage over a network connection could be an option for this).
More recently, online backup storage has become more common. Personally, I am slightly skeptical of these, mostly due to the loss of access control, but also because cloud services occasionally have service disruptions, and in some cases lose the data entrusted to them. In case you use such a service, my recommendation is to make sure the data are encrypted locally with a key not known to the service before they are uploaded; this prevents the service from accidentally or intentionally accessing your data, as well as preventing other unauthorized access. Another problem with such services is that they occasionally shut down business with little or no warning, so even if you use such a service, a local backup is recommended anyway. Backing up locally is also recommended when using online application services; these services are useful for working with others, but you might lose access when you most need the access.
There are various ways to perform a backup, from just using a simple copy command, to using more advanced backup applications in the OS, to purchasing commercial backup tools. Trial or Freeware versions of many such tools are frequently included on external harddrives.
My backup system
In my system at home I swap between two external SSD harddrives, and use Windows’s Backup software to manage the backup. Previously, I used a similar system with a commercial tool, but once I moved to Windows 10, I found that the Backup software in Windows seemed to work better for my purposes and I switched to it.
Better does not mean “perfect”, though. There are a few issues, but reasonably minor: 1) Swapping drives destroys the backup configuration, so I have to re-enter it when connecting the second drive. 2) The software does not resume backing up data from where it left off on the reconnected drive, causing it to use a lot more disk space, and requires occasional cleanup to remove old backups.
All this was manageable. At least until last week.
Microsoft breaks the backup
Recently, I finally caved in and allowed Windows 10 on my home computer to be updated to Feature Update 2004. Considering the problems that had been reported about loss of data in Chromium-based browsers, maybe I shouldn’t have, but Windows was now insisting on updating.
A couple of days after the update I switched backup disks, cleaned up some very old backups that were no longer needed, and set up the backup configuration again, and started a backup. A backup that failed! No data was copied to the drive.
I found no errors reported in the normal Event Viewer logs, until I dug down into the application specific logs for “File History backup”, where I found this meaningless warning: “Unusual condition was encountered during scanning user libraries for changes and performing backup of modified files for configuration <name of configuration file>”, with no information about what the “unusual condition” was.
As I usually do when having a problem like this, in order to find out what caused the problem, I started to test with the default configuration and then add more source drives for the backup to see which one broke the system.
The default configuration did copy those files, but it also copied a directory from one of my other drives, the main data drive, the copied directory is where I store all my photos. This directory was not part of the configuration. This directory may have been included because it is the configured default destination folder for the Windows photo import software.
However, when I added the rest of that drive to the list of folders to copy, no further files were copied (although a couple of days later some of the upper level folders did get backed up, none of the important folders were copied).
Removing that drive from the list, and adding the other drives I have for various tasks, projects, and software, those drives did get copied properly.
Going back to the problematic drive, further experiments did not succeed at backing up that drive more than the mentioned top level folders. Even experimentally adding some sibling folders of the Photo folder did not work; they weren’t even added to the list of folders to backup.
Eventually, I was forced to do a manual copy of that drive to a separate area of the backup drive, to make sure I did have a copy of it.
At present my conclusion is that in Feature update 2004 Microsoft did something to the Backup/File History software, and it broke my system for backups.
My initial guess at the cause of this problem is that the addition of the photo folder conflicts with adding the rest of the same drive to the list of files and folders to back up. Such overlapping lists should be merged, not create a fatal error.
A backup problem like this may not be a Security Vulnerability(TM), but it is definitely a Security Problem.
I have reported this via the Windows Feedback App, as well as to the @MicrosoftHelps Twitter account, but have so far not received any information about how to fix this problem (so, no help, so far).
Microsoft, there are some systems that should never break in production systems. The file system is one, account storage is another, and the backup software is one of the others that should never break. In this release it looks like you broke two such systems. And at least one is still broken 5-6 months after the public release!
Ars Technica is one of the major technology news sites I follow, as it carries a lot of interesting stories about computer, general technology, and science news.
Last week, however, reading the site became much more difficult.
In relation to the California Privacy law going into effect January 1st, the owner of Ars Technica (and Wired), Condé Nast, put up a pop-up dialog over the front pages of these sites (and maybe others), and required visitors to click through the dialog to access the sites.
The dialog displayed over Ars Technica’s front page
However, the click through did not take. On the next visit to the front page, the dialog showed up again. And on the next visit, and the next…
A couple of tweets to Ars Technica’s Twitter account has so far not resulted in any response. It seems like Ars Technica are not monitoring their mentions, and based on a previous case a few months ago (related to their new GDPR dialog popping up several times a week), they are not monitoring their DM channel, either.
I had an early suspicion about what was causing the problem. I have been browsing with third-party cookies disabled for the past couple of years, after I got tired of ads about products I had no intention to buy following me around the net for weeks on end.
Considering Ars Technica and Wired’s target audience, I would guess that a lot of their readers are disabling third-party cookies, too.
Except for one banking site, that have mostly worked fine. Until now.
A bit of testing determined that my initial guess about the cause was correct: The Condè Nast dialog requires that third-party cookies are enabled.
This means that in order to register “accept” of an update to Condè Nast’s privacy policy, the users have to permanently enable third-party cookies, allowing all web sites (not just Condé Nast’s) and all advertisers to track them across all sites on the net that are linked into their various tracking systems.
That isn’t a privacy improvement, it is a privacy invasion!
Condé Nast: Please fix this.
Update Jan 10: The Ars Technica site has now been fixed AFAICT. According to info I got yesterday, the problem also affected users of Privacy Badger.
Photo by Agustinus Nathaniel on Unsplash
Two weeks ago I posted an article about the occasional problems of getting false positives in security software fixed, and specifically about our recent problems when trying to solve a problem related to a Sophos security product. A user had reported being prevented from using Vivaldi to browse the net by their company’s firewall.
Some commenters thought we were either too hard on Sophos, or hadn’t properly checked the issue before contacting Sophos.
These comments ignore a few of the issues we mentioned:
We had a report about the users being blocked.
We also had information from the same report about Sophos customer support claiming we did not support an API, the implication being that we were being blocked because of this.
Either of these would be reason good enough to contact Sophos to learn about why this was happening, especially given that we should have the same API support as other Chromium based browsers.
We then spent 5 weeks not getting answers to our questions.
Part of our goal with the article was to inform Sophos publicly (just like we had at at least one occasion done privately) that we were not satisfied with how the process was going, and to try to get it escalated.
The next day it got escalated to a support manager, and we started getting real answers to our questions.
First of all, there was no central block by Sophos regarding Vivaldi; the block had been configured by the administrator of the customer installation. We are not yet clear on why the administrator did this, although our not being on the filtering feature support list has been mentioned as a possibility. This particular piece of information was never forwarded to us, and as far as we can tell was not provided to the original reporter, either.
The second part was that the API support was NOT something required to be supported by the browsers. The APIs in question concerned Windows API functionality used by Sophos to configure firewall and network filtering for specific applications.
This functionality is not presently enabled for Vivaldi, because those features had not been tested with Vivaldi. Sophos is now moving to get this functionality enabled and tested with Vivaldi, probably to be released in early Q1 2020.
A part of the confusion regarding Vivaldi and Sophos concerned this functionality, and some of it may have been caused by different understanding of phrases like “Product X is supported”. In many cases a vendor will write this and mean “We only answer support questions about X, not Y”, while most users will read it as “Since Y is not listed, Y does not work with this vendor’s product”.
Regarding Sophos, their page regarding their filtering functionality, they listed a number of browsers for which this feature was enabled (thus “supported”); it said nothing about whether or not other browsers worked on a system using Sophos.
Much of the rest of the confusion that developed in this case was likely caused by misunderstanding information provided to the people at the reporter’s company, and more details may then have been lost when they were passed on during the several steps it passed through before it got to us. A possible way to reduce such confusion is to always use email for questions and answers, any chat logs should be archived.
One of the things we realized in the aftermath of this is that our Bug reporting form and help pages did not ask for details about any third-party software that might be involved in the problem, and we have now updated the bug reporting help page to specify what we need in such cases: Product name and version, relevant error messages, and if available information about any support contacts, such as support case numbers.
The lack of product and version info about the installation was part of the problems we had when contacting Sophos support, since it made it difficult to get in touch with the right people.
We are quite satisfied with the responses from Sophos in the past two weeks.
False positives causing a legitimate application to be blocked is a common problem with security software, and if not handled properly and quickly, it is one that could hurt, or even destroy a security product’s credibility, or in the worst case, the credibility of the entire sector.
It is therefore very important that whenever a security vendor’s product is incorrectly flagging a legitimate product that the vendor resolve the issue within hours, or at most a couple of days of being notified about the problem. Such problems should really be handled with a priority just barely short of problems threatening the customer’s system (like security vulnerabilities).
If a user cannot use their chosen, legitimate products because a security product blocks it, they are far more likely to disable, or uninstall, the security product, than to change their chosen product.
If the problem is caused by some actual problem with the flagged product, the security vendor should immediately contact the application vendor with detailed information about what the problem is, and how to solve it.
Easier said than done
As an example of how to not go about handling such cases, consider this recent case.
About a month ago, in early September, the Vivaldi users at a small German company discovered that they were no longer able to use Vivaldi, since their Sophos firewall was blocking it.
They contacted Sophos customer support and were effectively told that “The block was a management decision”, “Vivaldi does not support content filtering”, “Vivaldi does not support a required API”, “Submit a feature request, we can’t do anything before we receive that” (the latter had been filed over a month before this case started).
No information was provided about which API support was “missing”, or why “management” had decided to block Vivaldi.
Since Vivaldi is based on Chromium, just like Google Chrome, if the blocking was really due to missing support for an API, then Sophos should be blocking Google Chrome as well. We have the same feature support as other Chromium-based browsers. The only real difference is that (e.g. on Windows) our executable is named “vivaldi.exe”, not “chrome.exe” and our UI is implemented differently.
After receiving the replies from Sophos, one of the users in the company reported the problem in a post to our German language forum, and it was then forwarded to those of us in the security group.
I decided to look into the Sophos support site, and did find their chat support, but after two hours of back and forth, being passed from one person to another, their response was effectively “We need a support ticket number, file it from the upload site”.
There were several problems with that upload site, mainly that there was no option to upload a file as “Affected vendor”. You had to be either a “registered user” or “evaluating before purchase”. It was also difficult to choose the right product or product category, and the upload size limit was 30 MB (Vivaldi’s installer is ~55MB), although an FTP option existed.
Since I could not upload Vivaldi’s installers, I uploaded an empty text file, and told them in the message where to get the installers. Their Labs people explained that they were not allowed to download installers from the Web.
After an FTP upload, and a few days wait, they reported that the “problem has been fixed”.
The users said “No, it hasn’t been fixed”.
55+ emails back and forth later (to Sophos and the user), direct involvement with the customer, and 5 weeks after this all started, the problem still hasn’t been resolved. Effectively, they have acted like a brick wall.
In my opinion Sophos has not handled the case well. They never told us, or the customer, what is causing the problem, and they have so far spent at least 5 weeks not fixing the problem, so they definitely did not drop “everything else” to solve it.
I recommend that all security software vendors check their processes to make sure they can handle false positives quickly and efficiently.
Problems I have seen during the process with Sophos
The support people kept assuming I was the customer using their product, and repeatedly asked for information I could not possibly provide. My suggestion is that they create a separate support ticket category for application vendors.
They were unwilling to contact the reporter via the forum thread, saying they were not allowed to do support except through their issue system. My suggestion is that they communicate with reporters through the reporters’ chosen channels, and then invite them to use the vendor’s own channels. This will improve the impression of their customer service.
As mentioned, the upload system is not suited to normal-sized applications, or affected vendors. The minimum size should be increased significantly, and I think they should offer SSH upload via SCP instead of FTP.
An unsophosticated test
While working on this article, I started thinking about the question of exactly how Sophos blocks Vivaldi. My conclusion based on what I know about other firewalls, was that the most likely method is to just check the process name which, as mentioned above, in our case is “vivaldi.exe” on Windows, not “chrome.exe”. It could be that they are doing something more sophosticated, but I doubted it.
So yesterday I created a special version of Vivaldi 2.8 where I undid the changes that rename our Windows executable to “vivaldi.exe”. Even if this experimental build would not be able to get through the firewall, we would learn something about just how sophosticated Sophos’ implementation is.
This morning we sent this special build to the reporter and asked him to run a quick test for us. He has just reported back that the special build was able to access the internet through the firewall.
For other affected Sophos users, the special build (which works as a Snapshot channel, so you might want to disable updates for this particular installation) is available for download here. It should be installed as a standalone version using the advanced installation dialog, NOT over the main Vivaldi installation.
Similar cases from the past
This is not the first time we have had similar problems, either in Vivaldi or back when many of us worked in Opera, and they are usually resolved quickly, without much publicity. For the most part an exchange of a couple of emails were enough to get the problem solved.
There were two cases that didn’t get resolved quickly, and which required a bit more work. One was the old 2003 Opera Bork edition targeting Microsoft and MSN, and the 2016 Vivaldi case when some AV software decided they did not like “Vivaldi Technologies AS” as a text string in our installer, “Vivaldi Technlogies AS” (without the first “o”-letter) worked fine. In both cases our public response caused the issues to be resolved very quickly.
In a more recent example, Eric Lawrence from Microsoft’s Chromium Edge team was trying to chase down why recent versions of a Chromium support executable was triggering warnings from a significant number of Anti-Virus scanners. Although he never actually found the problem (it disappeared in newer builds), as he closed in on what triggered the problem, it started to remind me about our 2016 case, which is why I sent him a link to our 2016 snapshot announcement, and it subsequently made a short appearance on Twitter.
For modern software developers, there are a number of must-have tools: An editor, a compiler (called a web browser by HTML/JS devs), and a debugger. Further, if you are developing a non-trivial project, especially as part of a team, you will need a version control system.
A version control system is a very important tool when developing software, as it maintains the history of your project, chronicling every change, whether small or major, and it allows you to share your code easily with others. Using the information stored by this system it is possible to specify the source code version to use for a public version of the product or to discover which modification introduced a bug (or fixed it).
There are many different version control systems available. Among the more common ones are CVS, SVN, Hg, and currently the most popular, Git.
All of these systems are generally implemented as command-line tools, and this lets the user perform many advanced actions, especially using scripts to repeat the operations. However, maintaining source code updates only via command line operations becomes difficult very quickly, it does not scale well. A graphical UI (GUI) for the version control system is needed for any major project.
Some of the systems, like Git, also have some basic GUI applications, but their usability is limited. This has opened up a market for more advanced version control GUI applications, such as the one I have used for 10 years, or so, SmartGit.
Syntevo’s SmartGit, like most such tools, has an advanced display of projects, updated files, conflicted files, differences between the currently stored version, and the currently edited version, graphical representation of the project history, etc.
All of this is very useful to developers, especially when they are working on big projects.
Five years ago I wanted to update to the then newest version of SmartGit, v6.5 (the most recent is v19), from my then current version, v4.6.
Unfortunately, I discovered that the SmartGit developers had made some UI changes that broke the tool for me.
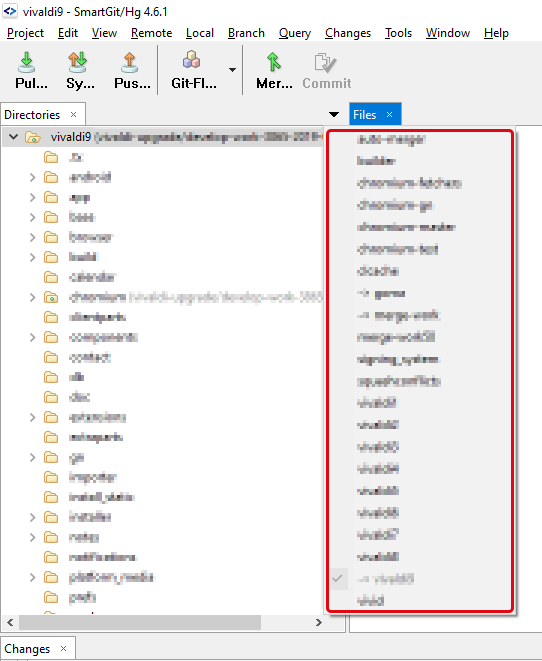
One of the UI features I use frequently is a dropdown menu on top of the directory explorer panel listing all the projects I am working on, and which allows me to easily open a second project in a new application window.
In the new version, they had removed this dropdown, and moved all the projects into the explorer panel, alongside the directory views, and the default operation was to open all of these in the same application window (it _is_ possible to open a second window). When you, like me, are working on 20+ various project checkouts, half of them having more than 500 000 files each, having more than one of them opened in the same application window is, in a word, unworkable. Even having the list of all the projects in that panel is in my opinion unworkable with a setup like mine.
I reported this issue to the developers at Syntevo, informing them that this was an upgrade blocker for me. Their answer boiled down to “Won’t fix it”. I responded with “Won’t upgrade”.
I have stayed with SmartGit 4.6 ever since, despite the other issues with it, such as it being slow, leaking memory, some of which could be due to it being implemented as a Java application.
I have explored other similar tools, but the ones that look most useful have one major problem: They all require that before you start, you must create an account with their code repository and log the application into it.
That is unacceptable to me, because I am not generally going to be using an external repository. We have our own local servers holding the repositories for our projects.
I do not mind buying a license for a useful product, but I do mind having to run a product logged into an external service, especially one I don’t need.
So, if Syntevo, could just fix the GUI in this area (and haven’t broken anything else important), they would sell at least one license, and since this would make the tool work better again for Chromium sized projects, they would likely sell even more licenses.